
awk(オーク)について
UNIX系OSを使っている人なら多分知ってると思いますが、awkコマンドはテキスト処理に非常に強力な威力を発揮してくれる「いにしえの神アプリ」だと言い切っても良いと思います。このスクリプト言語は、CSVなどのデータベース的な構造を持つテキストデータの扱いに特化していると言うのは安直かも知れないですが、むしろそう言い切った方が、awkを知らない人にとってはわかりやすいだろうという話です。(実際の所はスペース区切りの情報も上手くセパレート出来てしまうから応用範囲は広いのですが)
CSV【Comma Separated Values】形式は、そのまんまカンマで区切られたカラムの概念を持つレコード形式です。Excel等の表計算と比べて言えば列の区切りをカンマで表したテキストデータです。これを見やすくするためにExcelにCSVをインポートしたり、CSVエディタを使用したりすると表として見えるので、見やすく、編集もしやすくなります。行についてはもちろんレコードを表すことになります。つまりこれはデータベースのテーブル(配列)と同じ概念です。
データベースについて
表計算はデータを整理するのに都合の良いツールなのですが、案外、Excelをデータベース・テーブル的に使う人は少ないのが実情です。どちらかというと汎用文書作成アプリとして「見た目(印刷結果)を重視した文書作成」が主で、セル間の値を使った計算でさえ機能を使っていない人が多くて驚いてしまいます。Excel方眼紙なんて言葉も有りますし・・
私としてはデータベース・テーブル的に整形された膨大なデータ処理こそExcelの真骨頂だと思っているのですが、使い方は人それぞれなので強要は出来ませんしするつもりもありません。でもExcelの能力と機能を活用せずに手間がかかる管理をしている人を見ると、もったいないなぁというのが本音です。
とても人間の手だけで管理出来ない程の多くのデータをExcelで効率よく処理出来る人は私の言いたい事を理解していただけると思います。膨大なCSV形式のデータでもExcel等の表計算ソフトで開けば加工したり集計したりもチョイチョイと楽勝になるのです。
Excelの弱点というか改善されない不具合というか
ところが、Excelには厄介なことがあります。まず数字を勝手に数値形式として読み込むので、例えば「0001」 という値は、勝手に「1」に置き換えられてしまいます。これが桁数にも意味のある例えば商品コードだったりすると桁数を合わせるために頭を0で揃えるのは普通にあることです。
この様な書式になっているCSVファイルをを明示的にテキスト形式だと認識させるためには、ファイルの拡張子.csvを一度.txtに変更して、Excelからウィザードを働かせながらファイルを開く必要があります。ファイルの種類をcsv、txtとして取り込み、形式をテキストとして指定してやらなくてはなりません。ExcelのCSVファイルの扱いについては実に面倒な仕様でありマイクロソフトには過去に何度か要望したのですが一向に改善される気配がありません。(その代わり要らない機能が実装されてゴテゴテの肥大状態が現状でしょう)
そもそもCSV形式はテキストファイルなのだから、数値として扱うのは仕様がマズイと思うのです。テキストとして開いてくれる仕様ならExcelに拡張子.csvを関連付ける意味はあるのですが、数字を数値として勝手な解釈をしてしまう時点で関連付ける意味は無いし、トラブルの元となるのです。(私の知る範囲では、Excel2013の以前では解決していないし改善する気配も全くなさそうです。きっと今後も改善されないでしょうね・・)
膨大なデータ処理はさすがに表計算では無理かな
次に問題となるのは読み込み可能な行数とカラム(列)数です。Excel2007以降で劇的に拡張されましたが、Excel2003では6万数千行以上は開けないという制限がありました。これ以上のレコード数を持つ情報を扱うとなると手っ取り早くAccessに頼る事になるのが実情ですが、Accessを持ってないとお手上げです。
ちなみにフリーの表計算アプリ(OpenOffice.org)も同じ制限を持っていたのですが、最新版(バージョンは失念)でこの制限が改善されより多くのデータを含むファイルを開けるようになりました。ただしOpenOffice.orgのCalcでは、数万行のCSVを読み込ませると行の高さ調整中のままフリーズするという不具合が起きます・・・つまり使えないのです。
そこで、Cassavaや、KutoCSVエディタなどのCSV専用エディタを引っ張りだして来て使って見るのですが、これまた数万行となると動作が緩慢どころか、フリーズ症状となり、快適な編集作業は望めないのです。これだけPCの性能が上がったにもかかわらず、たかだか50MB程度のテキストデータであるCSV形式のファイルを快適に編集できるGUIのソフトウェアがいまだに無いのです。
テキスト処理はテキストエディタに任せるべき?
CSVのデータ構造を理解している人ならば、テキストエディタ(秀丸エディタ、EmEditor、K2Editorなど)で処理した方が軽快でミスも少ないと知っていると思います。しかしテキストエディタで編集するには慣れが必要です。なぜこのご時世に、CSV形式のデータを表の体裁にして表示してテキストエディタの様に快適に編集するツールが出てこないのか?ニーズが無い?
※CSVモードを持つテキストエディタ(MIFES等)も存在します
いや、そんなことはないと思います。なぜならこの世にはネットショップがどんどん増えている実情、サイトの商品情報などの更新はCSVファイルで行っているケースがかなり多いはずなのです。おそらCSV編集ツールのニーズはあるけど良いツールが無いので結局ズルズルとその惰性で進んでいるんだと思います。
そこで一歩先を行ける人は、Excelを捨てて、MS-AccessやFileMakerなどのデータベースアプリを使っての編集というのが現実的な話になります。実際Filemakerでショップデータを加工してアップロードしているという事例を結構耳にしましたし、私もAccessを使って商品データ(CSV)を一気に編集するツールは日常的に使っていました。でも、わざわざCSVファイルをデータベースに取り込んで、内部的に加工(編集)してエクスポートしてサイトにアップロードするのはどうなんでしょう?csvデータはテキストデータです。この手間は実に無駄が多いと私は思うのです。
そこでawkの出番ですよね
そこでCSV編集の筆頭に上がってくるのがスクリプト言語「awk」です。スクリプト言語と言うからにはプログラミング言語の一種とも言えます。これを言うと眉を顰める人がほとんどでしょう。しかし私も非プログラマーですからしてそこは安心して欲しいのです。awkは「プログラミングなんかわかんねーよ」って人でもその気さえあれば扱えるのです。「ちょっとの努力で覚えて後は楽をしたい」と言う気持ちを持っている私と同種の人ならば目的を達成出来るでしょう。私は先々凄く楽を出来るならちょっとした目先の努力は惜しみません。
awkにはカンマ区切りやスペース区切り等の、FS(フィールドセパレータ)に対応したデータ構造を持つテキストデータを効率良く処理する仕組みが組み込まれています。いや、むしろそういう用途の単に開発されたとしか思えないのです。CSVファイルの一括編集に最高のスクリプト言語だと私は思います。なにしろ私はプログラミングはまだまだ苦手です。だけどちょっと頑張った程度で単純なスクリプトを書ける程度のスキルです。シェルスクリプトやバッチファイルなんかは、やることをひとつずつ順番に記すだけで実行してくれるから大したスキルが要りません。
awkも手順を並べて記述していくだけで良いのであれば、十分対応できるのです。もちろんawkもれっきとしたプログラミング言語なので条件で分岐させてなんていう方法を使えば複雑な事も出来ます。でもそんなに難しい処理や複雑な事はさせなくても大抵のことは出来ます。単純な処理を行うスクリプトで処理して、処理した結果をまた別の単純な処理のスクリプトで加工します。
もちろん、これにはちょっとした数のデータなら手間かけた方がてっとり早いので無意味です。人間の手では到底扱え無い様な数のレコードを持つ情報なら、単純作業のスクリプトでも手間の分だけ分割すれば良いので意味が出てきます。実際、人力でやるなんてアホらしいからコンピュータを使うのです。
言い換えれば手作業で何度も繰り返しやってる事をawkでスクリプト化すれば良いのです。ちょっとした作業までスクリプト処理させる必要は無いと思いませんか?人間の手でちょいちょいと出来る事は手でやれば良いと思うのです。同じ作業を10万回とかアホらしくてやってられません。そういうのをスクリプトで処理するのです。
もちろん、より強力なPerlを理解している人はawkなんかに見向きする必要は無いでしょう。Perlの方が新しく洗練されていて柔軟だからです。だけどPerlの柔軟さが仇になる場合を想定できるでしょうか?私にはPerlは難しすぎて深くは理解できないです。Perlを身に着けようという気が起きません。プログラマーに任せるべきだと思っています。
だけどawkならなんとかなります。ベタだろうが泥臭かろうが、バカにされようが、手作業で(バカみたいに)繰り返しやることを一つずつスクリプトに手順どおり記せば良いのです。目的を達成するの(結果こそ)が最優先だと思うのです。言語の理想とかそんなのはプログラマじゃない私には関係ありません。結果が得られることが全てなのです。
なぜawkはマイナーなのか
私は、FreeBSD/LinuxでUNIX系のコマンドを覚え、ログの分析や管理をする為にawkを使うようになりましたが、いざ仕事で使用するCSVファイルがこのawkによって、非常に効率よく処理できることに気づいた時、awkやってて良かったと思いました。しかし同時に、なぜawkという考え(ツール)がもっとメジャーにならないのだろうか?と疑問に思ったのもあります。いくつか原因はあると思うのですが、
- 基本的にコマンドラインから実行するプログラムであること
- 比較的容易とは言えどもスクリプト言語にはプログラミング的思考が求められること
- Windows OSには標準では装備されていないこと
- 仕様が古くて柔軟性(拡張性)が乏しいとか・・(Perlとか使った方が話が早い)
まぁ、こんな程度なのかなと思います。
1.については容易に解決させることが出来ます。
Windows環境で「おーくの友だち」というユーティリティを使えば、gawkコマンドをGUIで使用することが出来ます。実によく出来ているので、設定が終わっている環境下では、gawkというコマンドの使い方を意識させない位に手軽です。
2.については、苦手意識というのが先に立っているだけのことだろうと思います。
事実私自身がそうであったからです。しかしことCSV形式のテキストデータを扱う場合においては、awkは実に良くできているので、思っているよりは容易に目的を達成することが出来ると思います。もちろん複雑な処理をするのであればそれ相応のアルゴリズムをスクリプト化しなくてはならないですが、単純作業を順番にさせていくのであれば、フローを書いてそれをスクリプトに記すことで実に合理的な処理が実現できるのです。毎日退屈な事務処理を強いられている人は一度チェックしてみる価値はあると思いますよ。
3.についてもほとんど問題ないでしょう。
gawkのWindows版がオープンソースで配布されているので、ありがたく使わせていただけば良いのです。gawk.exeを「おーくの友だち」と連携させるだけで容易に環境を準備できます。コマンドラインは意識しなくても良いので、「PATHを通す」という基本的な知識すら要らないです。何も知らないWindowsユーザーならPCにセットアップしてあげれば、普通のWindowsアプリだと思って使えます。裏でgawkというアプリが処理の要をこなしているとも知らず。(まぁアプリケーションとはコアな部分は見えないので、つまりこういうものなのだろうと想像します。)
4.については知らないです。どうでもいいです。
仕様が古くても目的を達成できたらそれでオッケーだと思います。手作業を毎日繰り返すなんてまっぴらごめんです。レガシーな言語にすがろうが、目的が果たせるならそれでいいじゃないですか。どんなに優れた言語でも使えないのでは意味がない。
さて、私の手元には、数万レコード(行)はまだちょろい。数十万レコードのCSVデータが来ることが度々あります。その情報(データ)を手作業で処理することは不可能だと断言出来ます。電子データで入手できている事を幸運だと思います。正規表現を使える置換機能を実装したテキストエディタ、 Excel、OpenOffice.orgのCalc、Access、FileMakerなどが無いともはや話にならないです。
しかしおそらくそれらのどれよりも速く処理を済ませることが出来る「無料」で軽量なツールがあるのだから使わない手は無いでしょう。恐ろしく単純で退屈で死にそうな処理作業を業務命令で突きつけられ、awkスクリプトを書き、数秒で処理を終わらせた時にコンピュータというツールの威力を再認識しました。また同じ作業があるなら、次からは既に作ったスクリプト処理を使って日々の単純作業をこなす業務の繰り返しだけです。空いた時間はほかの事に回せるなんて・・。なんと合理的な事だろうと思いませんか?
おーくの友だちを使う
「おーくの友だち」は簡単にセットアップできます。ダウンロードして来たzipファイルを解凍して、別途入手したgawk.exeを同一フォルダにCOPYします。任意のフォルダにおいても良いですが192KB程度の小さなプログラムなのであちこちに存在しても影響は無いです。Fowawk111フォルダに一緒に入れておくのが私流です。それにはシステム管理者としての経験(ノウハウ)も入っています。USBメモリーに入れておいても良いかも知れないですね。
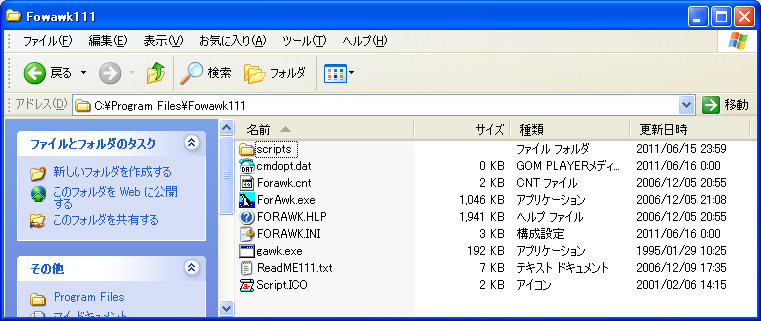
awkの実行ファイルの場所を定義(PATH設定)する
おーくの友だちはawkを便利に使うための支援ツールです。言い換えるとユーザーインターフェースと言えると思います。おーくの友だちの環境設定でgawk.exeの場所を設定しなくてはならないので、ForAwk.exeを実行して、「ファイル」-「環境設定」をメニューから実行し、設定画面を開きます。そしてawk.exeの所在を設定します。この時点ではPATHがフルパスで記録されるので、「set」をクリックして確定させておーくの友だちを終了します。
FORAWK.INIというファイルがあるのでメモ帳で開きます。そして下記の部分を書き換えて保存すると便利になります。
Path=C:\Program Files\Fowawk111\gawk.exe書き替えます
Path=gawk.exeたったこれだけのことですが、ForAwk.exeと同一ディレクトリにgawk.exeが有るという環境設定になったので、Fowawk111フォルダを移動させて、仮にデスクトップに置いたとしてもそのまま使用し続けられます。つまりUSBメモリーに保存して持ち歩いて別のWindowsパソコンで使うことも出来ます。
gawkのフォルダを残しておきたい場合
フォルダ構成を崩したくない場合は、下図の様にすればPATHが通ります。相対PATH指定ということですね。好みに応じて設定すれば良いです。
Path=gawkm115\gawk.exe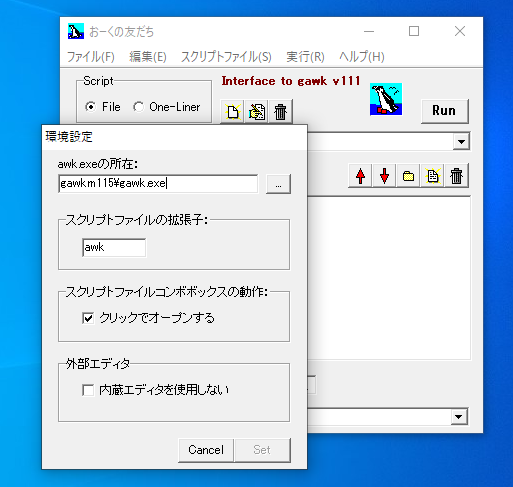
職場の管理者の場合は、この設定をしておけばOSがWindows XPだろうが、Windows7だろうが関係なしに持っていけるので便利だと私は感じています。ただし、当方のWindows7 32bit環境では問題なく動作しましたが、64bit版ではgawk.exeが動作しないと言う情報もある様です。
追記:64bit版Windows10では、保存するフォルダによってはスクリプトファイルがプルダウンに表示されない様です。おそらくアクセス権限(ACL)による制限だと思うのですが、面倒なので私はUSBメモリーに保存したものを使用しています。
見た目Windowsアプリですね
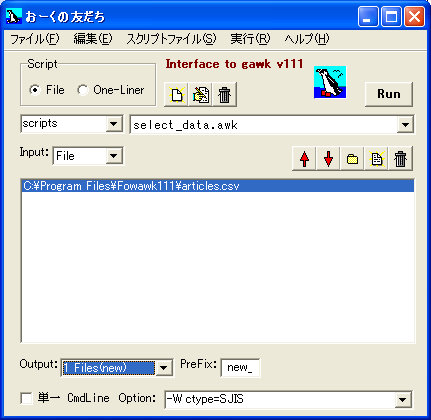
- スクリプトはどんどん追加して行けるし、プルダウンから選ぶことが出来る。
- スクリプトの書式はOne-Liner(一行野郎)でも可能。
- 処理したい対象ファイルは、広い枠の中にドラッグ&ドロップで放り込めばパスを認識してくれる。もちろん複数ファイルに処理を行うことも可能。
- Runで対象データに対して処理(スクリプト)が適用される。
- 結果の出力先はOutputで選べるが、上図の場合は、元ファイル名にPreFixが付加されて、new_articles.csvとして保存される。
- gawk.exeがSJISにしか対応していないので、処理できるデータの文字コードはSJISのみとなるみたい。(Optin指定で「-W ctype=UTF8」とすれば対応できるかも知れないが未確認。)
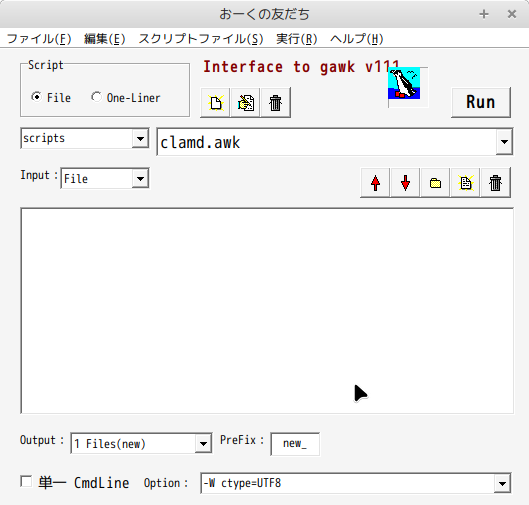
Optionはプルダウンで簡単に指定できる(下図)
最後に
見てのとおり、処理をさせたい対象ファイルの順序も変更できるし、至れり尽くせりかつ必要なUIは揃っている秀逸なフロントエンドアプリケーションだと私は思います。とても裏で「いにしえ」のawkというコンパクトなプログラムがテキスト処理を恐ろしく高速にこなしてるとは到底思えないのです。
ちなみに20万行(レコード)のCSVデータに、2つの単純処理を適用させてみたところ、5秒ほどで処理が終わりました。使ったマシンのCPUはCore i7-870ですが、比較的古いマシンでもそんなに待たされることは無いだろうと思います。仮に数分待たされたとしても別に良いじゃないですか。コーヒーでも飲んでリフレッシュしましょう。それでもExcelやWordにマクロ処理を実行させてとか・・・そんな方法に比べれば一瞬で終わると思います。
素晴らしくコンパクトで軽量なプログラムとそれを強力にサポートする秀逸なフロントエンドの組み合わせだと思います。おーくの友だちがあるという点でWindowsプラットフォームのポイントアップだなと私は評価しています。コマンドからの指定ももちろん便利だとわかった上でLinux等のPC-UNIXでも同じ様な支援ツールを作って貰えないかなと思ってます。
追記
「おーくの友だち」はNifty(ニフティ)がHPサービスを廃止した際に消えてしまった様です。この開発者さんが別のサイトで公開してくれるのを期待していますが、待っていても公開されないので開発やサポートの継続を放棄したものと思われます。しかしながら著作権は作者が持っていますので、私は保有しているファイルを大切に保管しています。
(以前のURLリンク切れ)
http://homepage2.nifty.com/mozu/winToy/winToy.html
サイトが移転されています!

現在「Forawk111.zip」ダウンロード出来るURL
Winのおもちゃからはダウンロードリンクが間違っているのでクリックしただけではダウンロード出来ませんが、「Forawk111.zip」は公開してくれているのでダウンロード可能です。単純にサイトを移転した時にリンクを張るのをミスってるだけみたいです。メールしてみたのですが返信も来ないので開発者さんがメールを読んでくれてないみたいです・・
勝手ながら現在ダウンロード出来るリンクを記しておきます。
Windows10以降では実行権限の課題あり
トラブル情報として記しますが、Windows 10 64bitで使用すると、スクリプトファイルを選ぶプルダウンにリストアップされない不具合があり、これはもうだめかと諦めかけました。しかしUSBメモリーに保存しているexeを実行してみたところ問題なく使用出来ました。ファイルへのアクセス権限がOSの変更でシビアになっている様です。
また、「おーくの友だち」のユニークで評価すべき点は、UNIX/Linuxのawkコマンドから単純にワイルドカード指定した膨大な数のファイルを処理するとオーバーフローするのに対して、「おーくの友だち」であればオーバーフローが起こりません。おそらく「おーくの友だち」がファイルを一つずつ読み込んで処理して、また次のファイルを読み込んでと順繰りにループ処理しているものと思われます。
もちろんUNIX/Linuxでも順繰りにファイルを読み込んで処理した結果をリダイレクトさせればこの問題は回避出来ますが、「おーくの友だち」がその課題をWindowsアプリの方で解決してくれている点も素晴らしいと思いました。非プログラマに優しい優秀なツールだとつくづく思います。
LinuxのWine環境上でも動作しました。




コメント